The Thesis: The Challenge & The Goal
The primary manufacturing bottleneck for a key therapeutic was the inherent variability in upstream bioreactor yield. Operators lacked real time insight into how initial batch parameters (feed composition, inoculation density, and temperature profile) would ultimately affect final harvest titer, leading to sub optimal performance and costly re work.
The goal was to move beyond reactive control to a predictive state by designing and deploying an analytical model capable of forecasting final yield with high accuracy ($R^2 > 0.90$) based on data collected within the first 48 hours of the 14-day process.
My Role & Contribution
I led the Advanced Data Analytics Initiative, serving as the technical interface between the Manufacturing Data Platform team and the Process Development scientists.
- Role: Lead Data Scientist & Chemical Engineering Process Expert
- Consolidated and cleansed 5 years of historical batch data from disparate sources (LIMS, SCADA) into a single, structured dataset.
- Engineered over 20 features, transforming raw time series data (e.g., pH slopes, dissolved oxygen integral) into predictive variables.
- Developed and validated a complex machine learning model (Random Forest Regression) to predict final titer.
- Deployed the validated model into a live dashboard used by manufacturing supervisors for real time decision support.
Visual Evidence & Interpretation
Model Performance: Actual vs. Predicted Yield
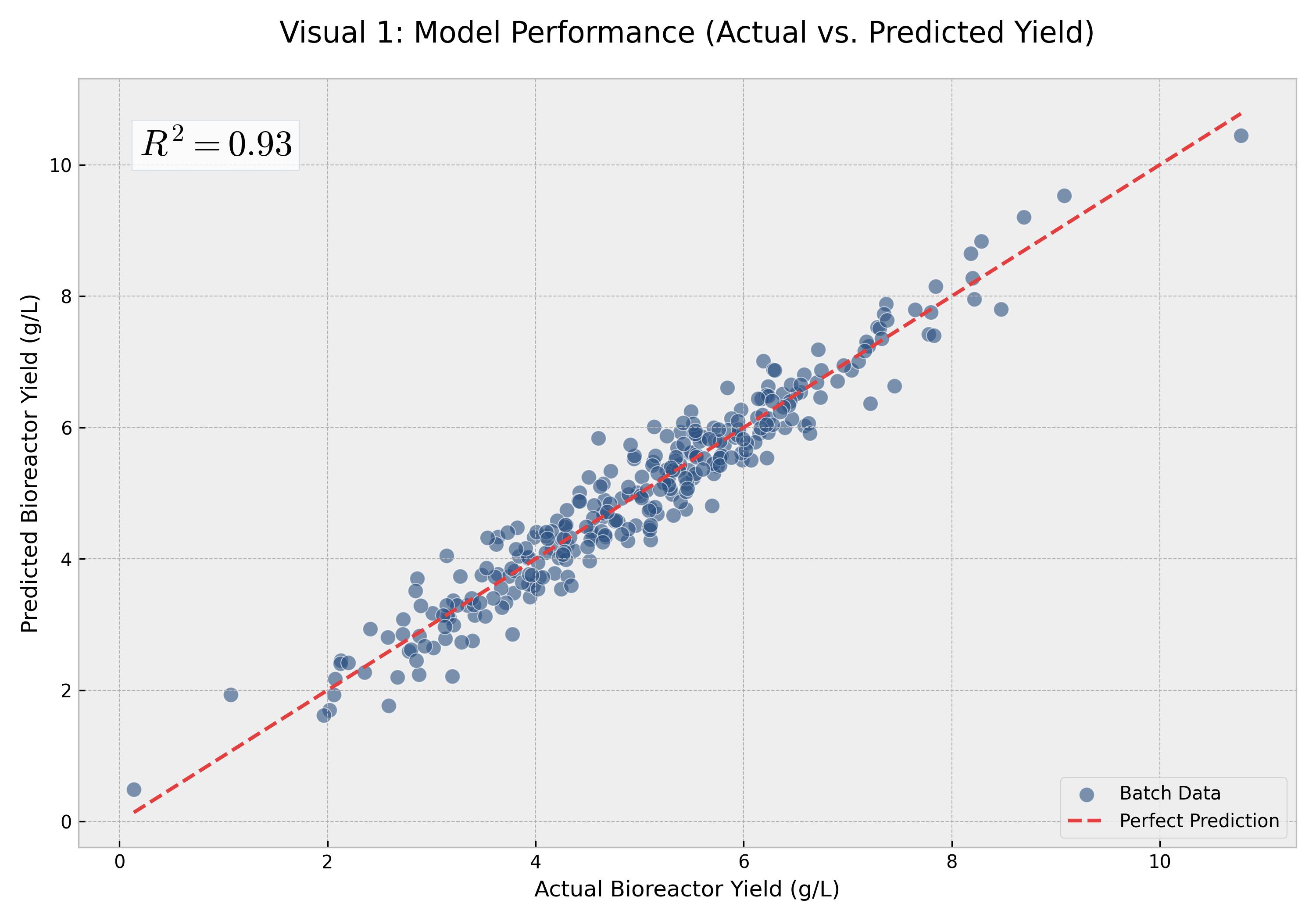
\textit{Caption:} Comparison of the model's predicted yield against the actual historical yield, confirming high confidence ($R^2=0.93$).
Impact on Quality: Reduction in Below Target Batches
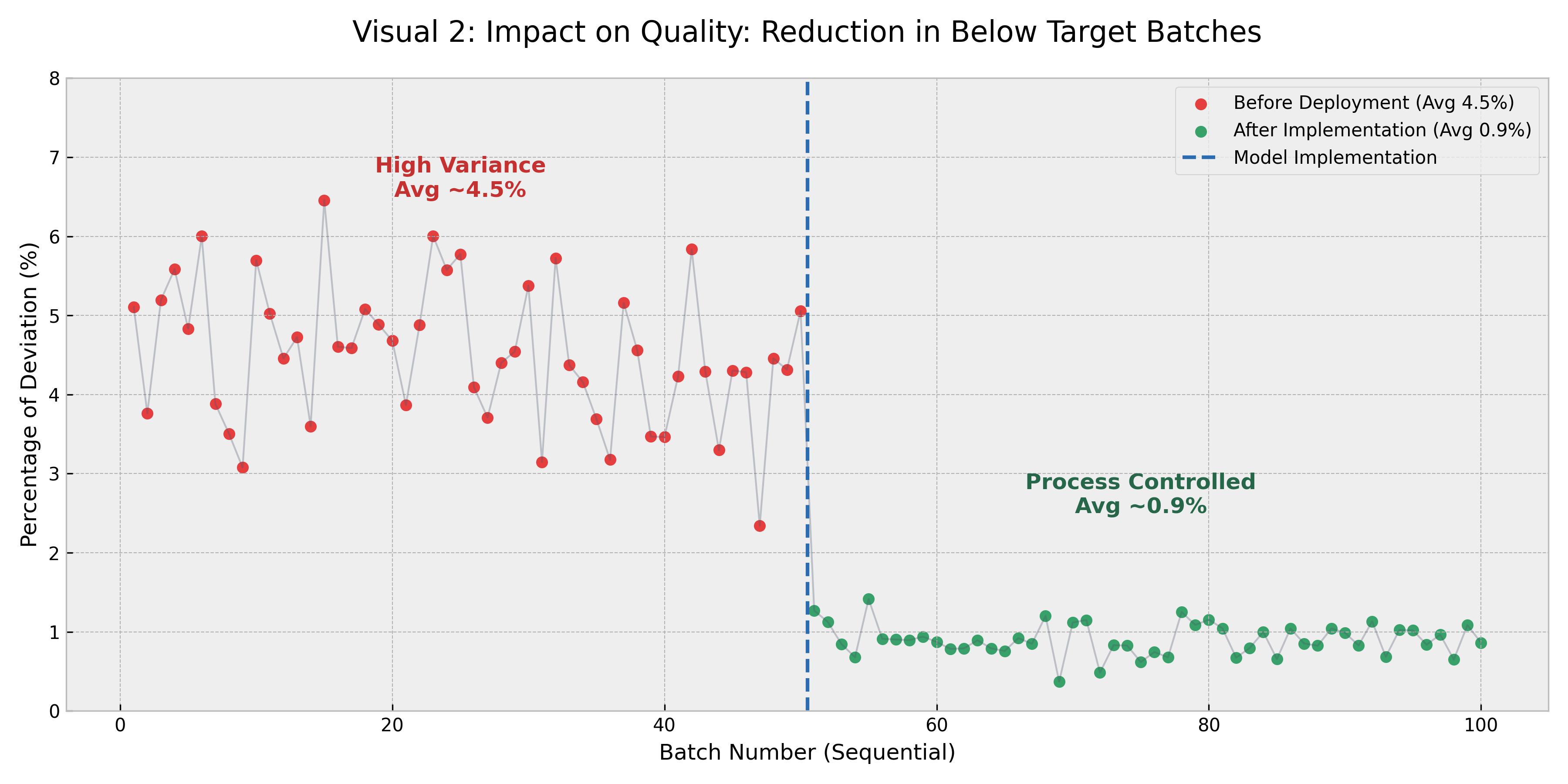
\textit{Caption:} Time series showing the sharp reduction in batches failing to meet the minimum yield target following the model's implementation.
The Impact: Results & Metrics
The successful deployment of the predictive model delivered substantial and measurable value to manufacturing operations:
- Predictive Accuracy: Achieved a model accuracy of $R^2 = 0.93$, allowing for reliable yield forecasting 10 days in advance.
- Waste Reduction: Reduced the incidence of 'Below Target Yield' batches by 60%, significantly reducing the need for expensive re batches.
- Financial Savings: The ability to prevent deviations through targeted intervention resulted in an estimated $2.1M in annual savings based on re batch and raw material costs.
- Process Understanding: The model's feature importance ranking formally quantified the effect of previously qualitative process assumptions.
Tech Stack & Tools
- Python (Pandas, NumPy, Scikit Learn)
- Random Forest Regression
- Tableau, Jupyter Notebooks
- LIMS, SCADA systems, Process Data Historians